Almost all leading planning and business intelligence (BI) solutions available in the industry offer a basic ETL (Extract, Transform, Load) infrastructure. This typically allows connection to standard data sources such as flat files or traditional databases, with simple transformation capabilities before loading data into their platform. For more customized data extraction and complex transformations, these companies often provide additional services through consulting agreements.
In most cases, these additional services come with a substantial one-time fee, on top of the regular subscription cost for using the platform. This approach aligns with their business strategy, as they prefer to focus on their core offerings, which generate the majority of their revenue. Additionally, they may be reluctant to allocate resources for customized data integration for only a handful of clients.
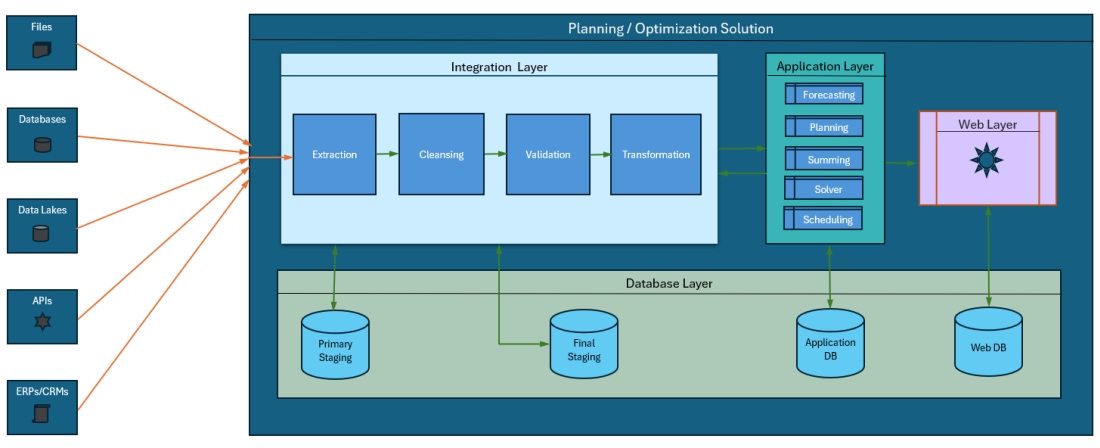
Below is a typical data flow diagram showcasing a standard data integration process developed by the planning or BI solution providers' teams. In this setup, their integration layer handles data extraction, cleansing, validation, and transformation before loading the data into their application layer.
When OptiLnX is introduced, all these integration stages can be managed within OptiLnX, enabling the planning or BI solution providers to perform a simple extraction from the OptiLnX DataHub. The data in the OptiLnX DataHub is already cleansed, validated, and transformed, ready to be fed directly into their application layer.
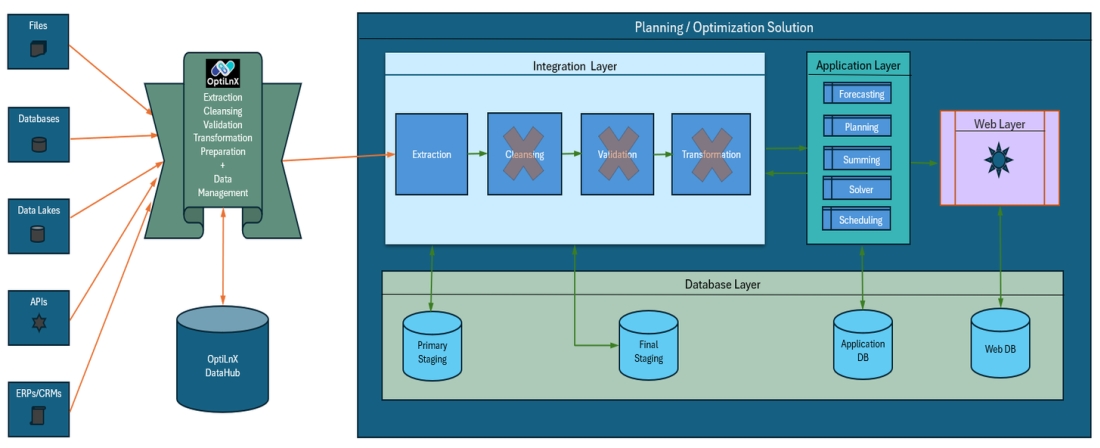
By utilizing OptiLnX for your data integration needs, you gain greater control, flexibility, and efficiency, leading to a more streamlined and cost-effective data management process.
Here are the standout features of OptiLnX DataHub:




Reach out to us